
Oracle使用正则表达式的4个主要函数:
1、regexp_like 只能用于条件表达式,和 like 类似,但是使用的正则表达式进行匹配,语法很简单: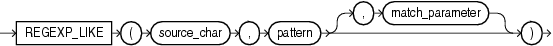
2、regexp_substr 函数,和 substr 类似,用于拾取合符正则表达式描述的字符子串,语法如下: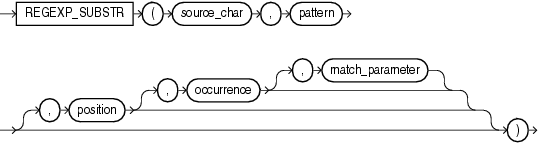
3、regexp_instr 函数,和 instr 类似,用于标定符合正则表达式的字符子串的开始位置,语法如下: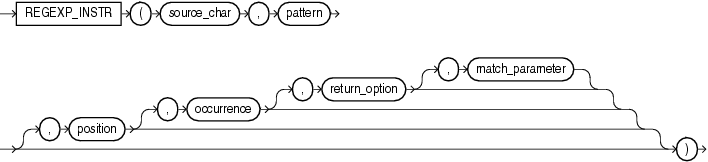
4、regexp_replace 函数,和 replace 类似,用于替换符合正则表达式的字符串,语法如下: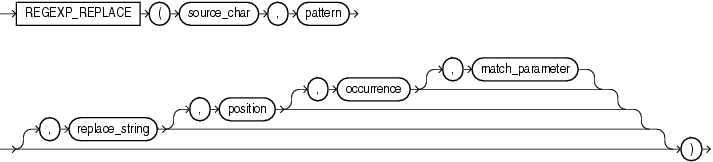
这里解析一下几个参数的含义:
1、source_char,输入的字符串,可以是列名或者字符串常量、变量。
2、pattern,正则表达式。
3、match_parameter,匹配选项。
取值范围: i:大小写不敏感; c:大小写敏感;n:点号 . 不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。
4、position,标识从第几个字符开始正则表达式匹配。
5、occurrence,标识第几个匹配组。
6、replace_string,替换的字符串。
示例:
基础数据准备
1 | -- 创建表及测试数据 |
regexp_like
1 | -- regexp_like示例 |
regexp_substr
1 | -- regexp_substr示例1 |
查询结果: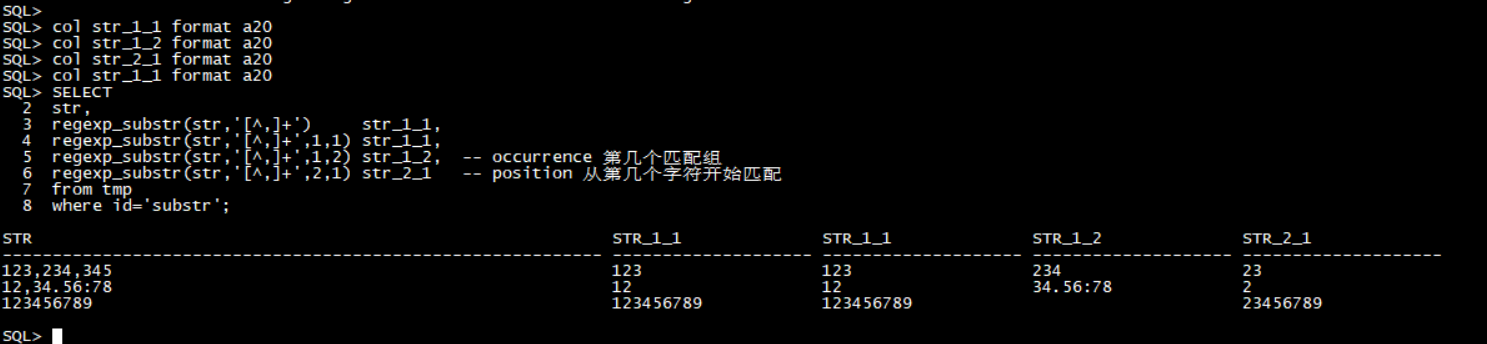
1 | -- regexp_substr示例2 |
查询结果: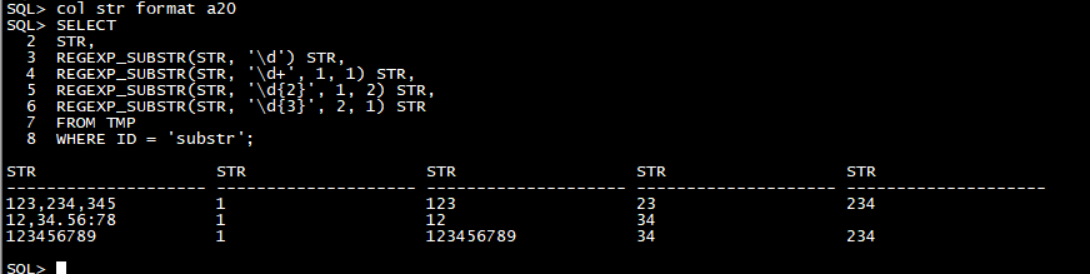
regexp_instr
略,以后补充。
regexp_replace
1 | -- regexp_replace示例 |
查询结果:
综合示例
1 | -- 建表 |
查询结果: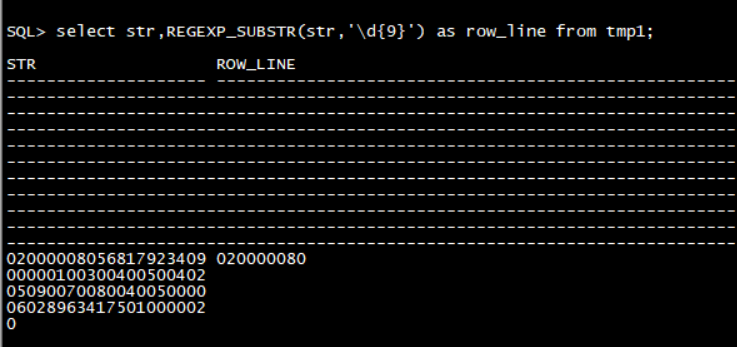
参考资源:
https://www.cnblogs.com/suinlove/p/3981454.html
https://docs.oracle.com/database/121/SQLRF/conditions007.htm#SQLRF00501

